Consumer poll 模型
Consumer poll 方法的真正实现是在 pollOnce() 方法中,一次 poll 过程,包括检查新的数据、做一些必要的 commit 以及 offset 重置操作。
1 | /** |
在这里,我们把一个 pollOnce 模型分为6个部分,这里简单介绍一下:
- coordinator.poll():连接 GroupCoordinator,并发送 join-group、sync-group 请求,加入 group 成功,并获取其分配的 tp 列表;,如果设置了自动 commit,也会在这一步进行 commit,总之,对于一个新建的 group,group 状态将会从 Empty –> PreparingRebalance –> AwaiSync –> Stable;
- updateFetchPositions(): 在上一步中已经获取到了这个 consumer 实例要订阅的 topic-partition list,这一步更新其 fetch-position offset,以便进行拉取;
- fetcher.fetchedRecords():返回其 fetched records,并更新其 fetch-position offset,只有在 offset-commit 时(自动 commit 时,是在第一步实现的),才会更新其 committed offset;
- fetcher.sendFetches():只要订阅的 topic-partition list 没有未处理的 fetch 请求,就发送对这个 topic-partition 的 fetch 请求,在真正发送时,还是会按 node 级别去发送,leader 是同一个 node 的 topic-partition 会合成一个请求去发送;
- client.poll():调用底层 NetworkClient 提供的接口去发送相应的请求;
- oordinator.needRejoin():如果当前实例分配的 topic-partition 列表发送了变化,那么这个 consumer group 就需要进行 rebalance。
注意:
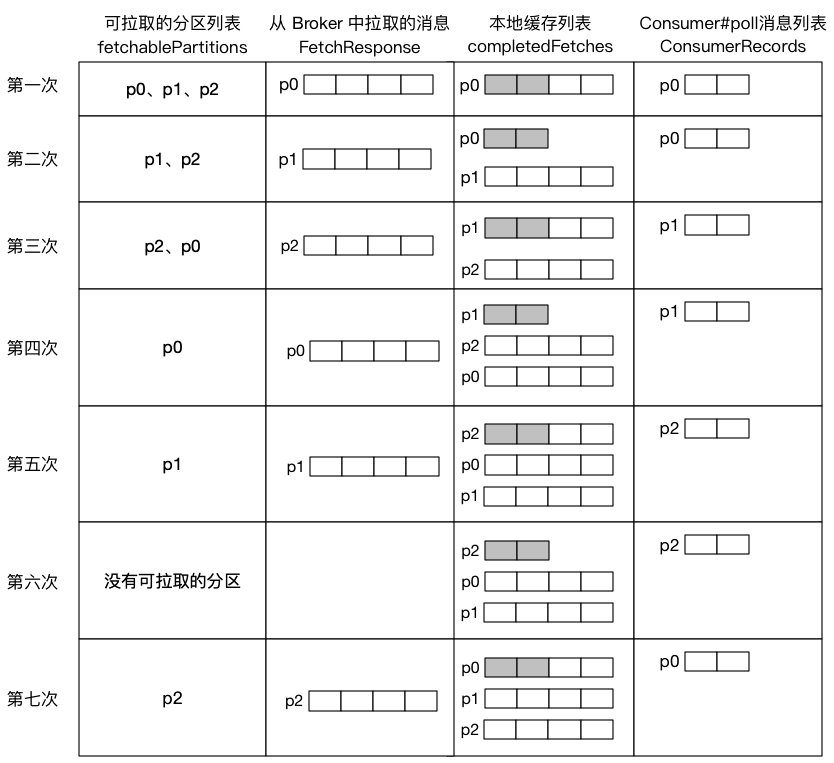
其实 Kafka 消费者在拉取消息过程中,有两条线程在工作,其中用户主线程调用 pollForFetches 方法从缓存中获取消息消费,在获取消息后,会再调用 ConsumerNetworkClient#poll 方法从 Broker 发送拉取请求,然后将拉取到的消息缓存到本地,这里为什么在拉取完消息后,会主动调用 ConsumerNetworkClient#poll 方法呢?我想这里的目的是为了下次 poll 的时候可以立即从缓存中拉取消息。
当缓存中还存在中还存在某个分区的消息数据时,消费者不会继续对该分区进行拉取请求,直到该分区的本地缓存被消费完,才会继续发送拉取请求。假设某消费者监听三个分区,每个分区每次从 Broker 中拉取 4 条消息,用户每次从本地缓存中获取 2 条消息: