produce 请求处理整体流程
在 Producer Client 端,Producer 会维护一个 ConcurrentMap<TopicPartition, Deque<RecordBatch>> batches 的变量,然后会根据 topic-partition 的 leader 信息,将 leader 在同一台机器上的 batch 放在一个 request 中,发送到 server,这样可以节省很多网络开销,提高发送效率。
在发送 Produce 的请求里,Client 是把一个 Map<TopicPartition, MemoryRecords> 类型的 produceRecordsByPartition 作为内容发送给了 Server 端,那么 Server 端是如何处理这个请求的呢?
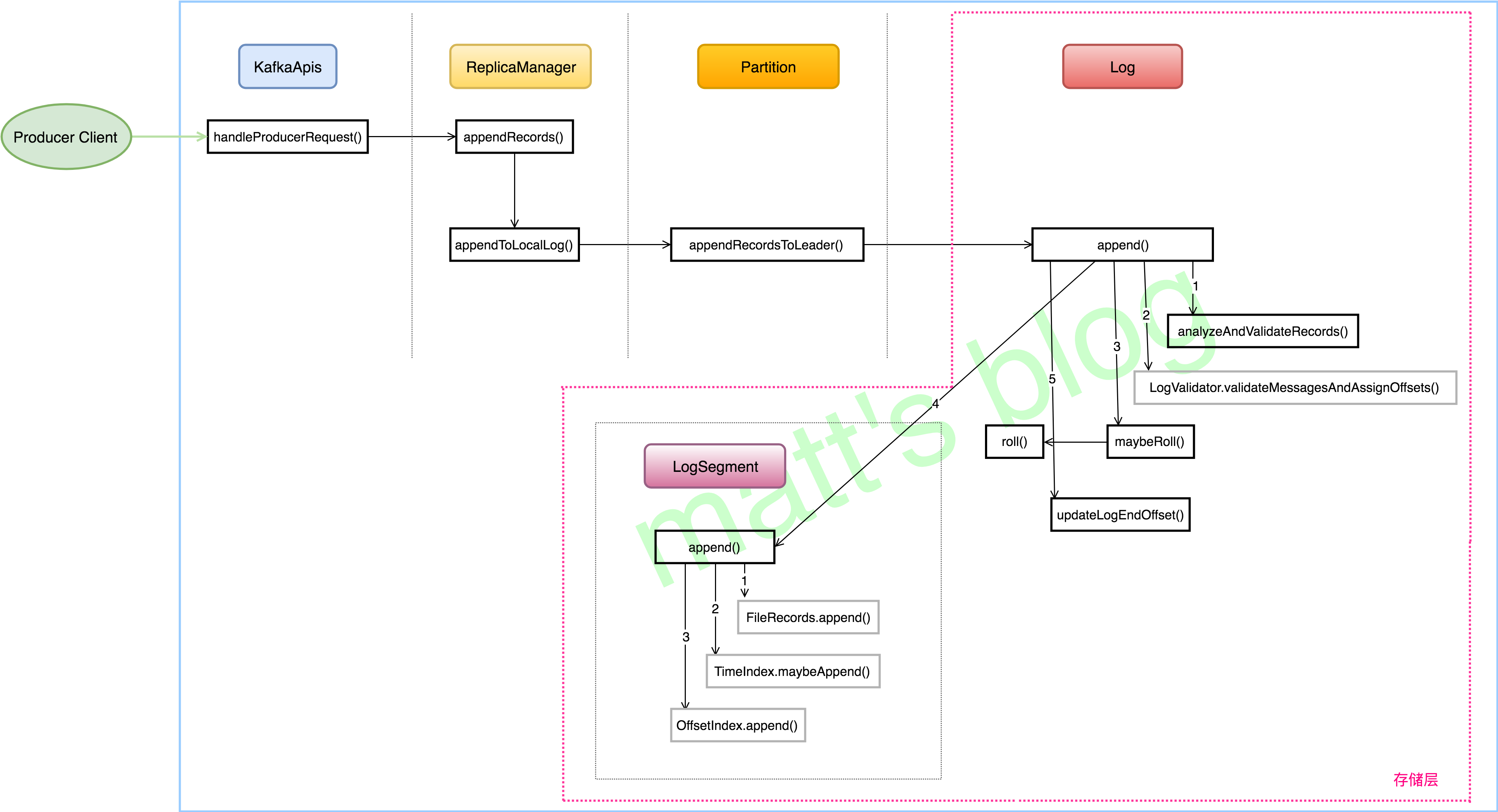
Broker 在收到 Produce 请求后,会有一个 KafkaApis 进行处理,KafkaApis 是 Server 端处理所有请求的入口,它会负责将请求的具体处理交给相应的组件进行处理,从上图可以看到 Produce 请求是交给了 ReplicaManager 对象进行处理了。
Server 端处理
KafkaApis 处理 Produce 请求
KafkaApis 处理 produce 请求是在 handleProducerRequest() 方法中完成,总体来说,处理过程是(在权限系统的情况下):
1. 查看 topic 是否存在,以及 client 是否有相应的 Describe 权限;(Describe 权限:如果用户在指定主题上具有 Describe 权限,则会列出该主题。)
2. 对于已经有 Describe 权限的 topic 查看是否有 Write 权限;
3. 调用 replicaManager.appendRecords() 方法向有 Write 权限的 topic-partition 追加相应的 record。
ReplicaManager
ReplicaManager 顾名思义,它就是副本管理器,副本管理器的作用是管理这台 broker 上的所有副本(replica)。在 Kafka 中,每个副本(replica)都会跟日志实例(Log 对象)一一对应,一个副本会对应一个 Log 对象。
Kafka Server 在启动的时候,会创建 ReplicaManager 对象,如下所示。在 ReplicaManager 的构造方法中,它需要 LogManager 作为成员变量。
ReplicaManager 的并不负责具体的日志创建,它只是管理 Broker 上的所有分区(也就是图中下一步的那个 Partition 对象)。在创建 Partition 对象时,它需要 ReplicaManager 的 logManager 对象,Partition 会通过这个 logManager 对象为每个 replica 创建对应的日志。
ReplicaManager 与 LogManger 对比如下:

appendRecords() 实现
appendRecords() 的实现主要分为以下几步:
1. 首先判断 acks 设置是否有效(-1,0,1三个值有效),无效的话直接返回异常,不再处理;
2. acks 设置有效的话,调用 appendToLocalLog() 方法将 records 追加到本地对应的 log 对象中;
3. appendToLocalLog() 处理完后,如果发现 clients 设置的 acks=-1,即需要 isr 的其他的副本同步完成才能返回 response,那么就会创建一个 DelayedProduce 对象,等待 isr 的其他副本进行同步,否则的话直接返回追加的结果。
appendToLocalLog() 实现
appendToLocalLog() 的实现如下:
1. 首先判断要写的 topic 是不是 Kafka 内置的 topic,内置的 topic 是不允许 Producer 写入的;
2. 先查找 topic-partition 对应的 Partition 对象,如果在 allPartitions 中查找到了对应的 partition,那么直接调用 partition.appendRecordsToLeader() 方法追加相应的 records,否则会向 client 抛出异常。
Partition.appendRecordsToLeader() 方法
ReplicaManager 在追加 records 时,调用的是 Partition 的 appendRecordsToLeader() 方法。
在这个方法里,会根据 topic 的 min.isrs 配置以及当前这个 partition 的 isr 情况判断是否可以写入,如果不满足条件,就会抛出 NotEnoughReplicasException 的异常,如果满足条件,就会调用 log.append() 向 replica 追加日志。
存储层
log对象
在上面有过一些介绍,每个 replica 会对应一个 log 对象,log 对象是管理当前分区的一个单位,它会包含这个分区的所有 segment 文件(包括对应的 offset 索引和时间戳索引文件),它会提供一些增删查的方法。
在 Log 对象的初始化时,有三个变量是比较重要的:
- nextOffsetMetadata:可以叫做下一个偏移量元数据,它包括 activeSegment 的下一条消息的偏移量,该 activeSegment 的基准偏移量及日志分段的大小;
- activeSegment:指的是该 Log 管理的 segments 中那个最新的 segment(这里叫做活跃的 segment),一个 Log 中只会有一个活跃的 segment,其他的 segment 都已经被持久化到磁盘了;
- logEndOffset:表示下一条消息的 offset,它取自 nextOffsetMetadata 的 offset,实际上就是活动日志分段的下一个偏移量。
日志写入
Server 将每个分区的消息追加到日志中时,是以 segment 为单位的,当 segment 的大小到达阈值大小之后,会滚动新建一个日志分段(segment)保存新的消息,而分区的消息总是追加到最新的日志分段(也就是 activeSegment)中。每个日志分段都会有一个基准偏移量(segmentBaseOffset,或者叫做 baseOffset),这个基准偏移量就是分区级别的绝对偏移量,而且这个值在日志分段是固定的。有了这个基准偏移量,就可以计算出来每条消息在分区中的绝对偏移量,最后把数据以及对应的绝对偏移量写到日志文件中。
日志分段
在 Log 的 append() 方法中,会调用 maybeRoll() 方法来判断是否需要进行相应日志分段操作
是否需要创建新的日志分段,有下面几种情况:
当前日志分段的大小加上消息的大小超过了日志分段的阈值(log.segment.bytes);
距离上次创建日志分段的时间达到了一定的阈值(log.roll.hours),并且数据文件有数据;
索引文件满了;
时间索引文件满了;
最大的 offset,其相对偏移量超过了正整数的阈值。
创建一个 segment 对象,真正的实现是在 Log 的 roll() 方法中,也就是上面的方法中,创建 segment 对象,主要包括三部分:数据文件、offset 索引文件和 time 索引文件。
offset索引文件
这里顺便讲述一下 offset 索引文件,Kafka 的索引文件有下面一个特点:
采用 绝对偏移量+相对偏移量 的方式进行存储的,每个 segment 最开始绝对偏移量也是其基准偏移量;
数据文件每隔一定的大小创建一个索引条目,而不是每条消息会创建索引条目,通过 index.interval.bytes 来配置,默认是 4096,也就是4KB;
是稀疏索引,可以放到内存中加快查找,是有序的,可以使用二分法进行查找。
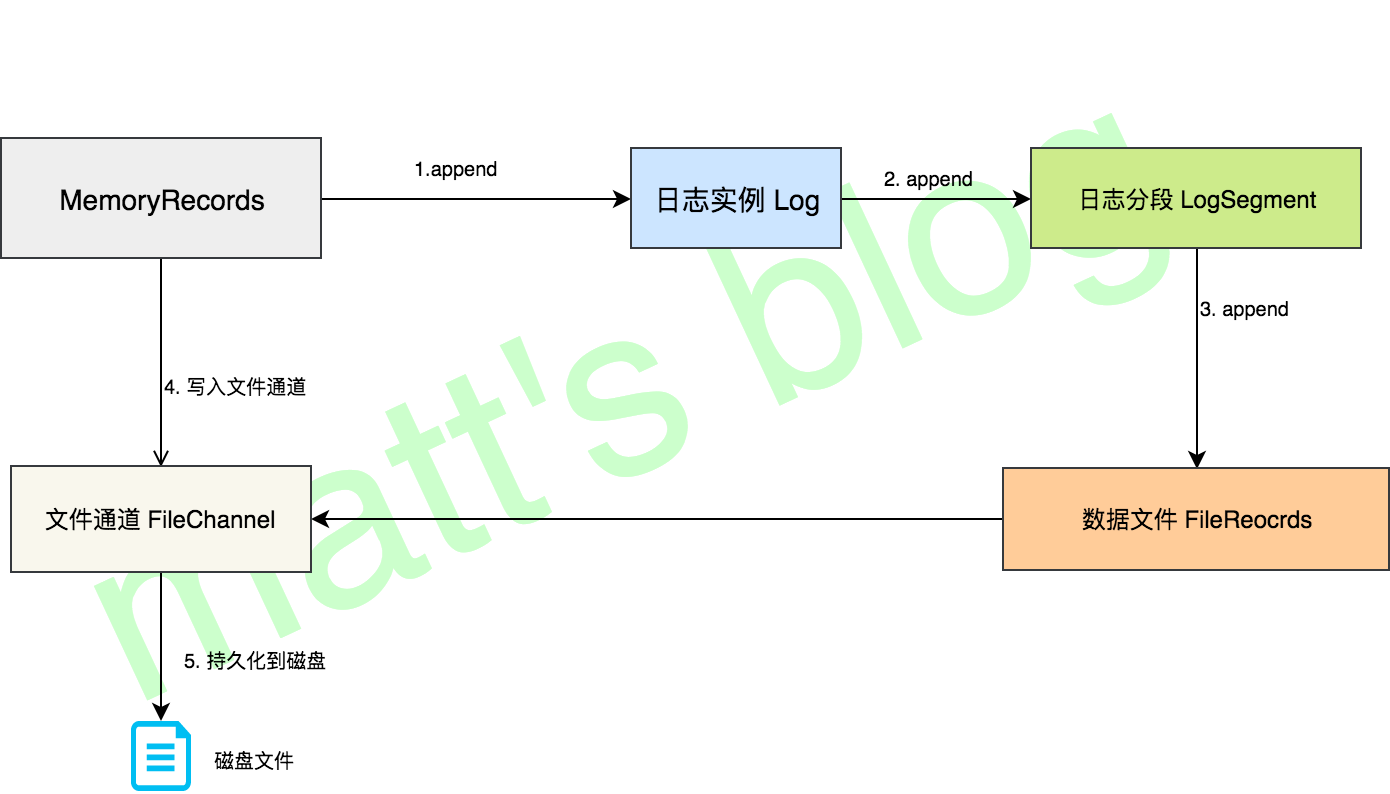
LogSegment 写入
真正的日志写入,还是在 LogSegment 的 append() 方法中完成的,LogSegment 会跟 Kafka 最底层的文件通道、mmap 打交道。