Fetch 请求处理的整体流程
Fetch 请求的来源
- Consumer Fetch 请求
- Replica 同步 Fetch 请求
Server 端的处理
KafkaApis 如何处理 Fetch 请求
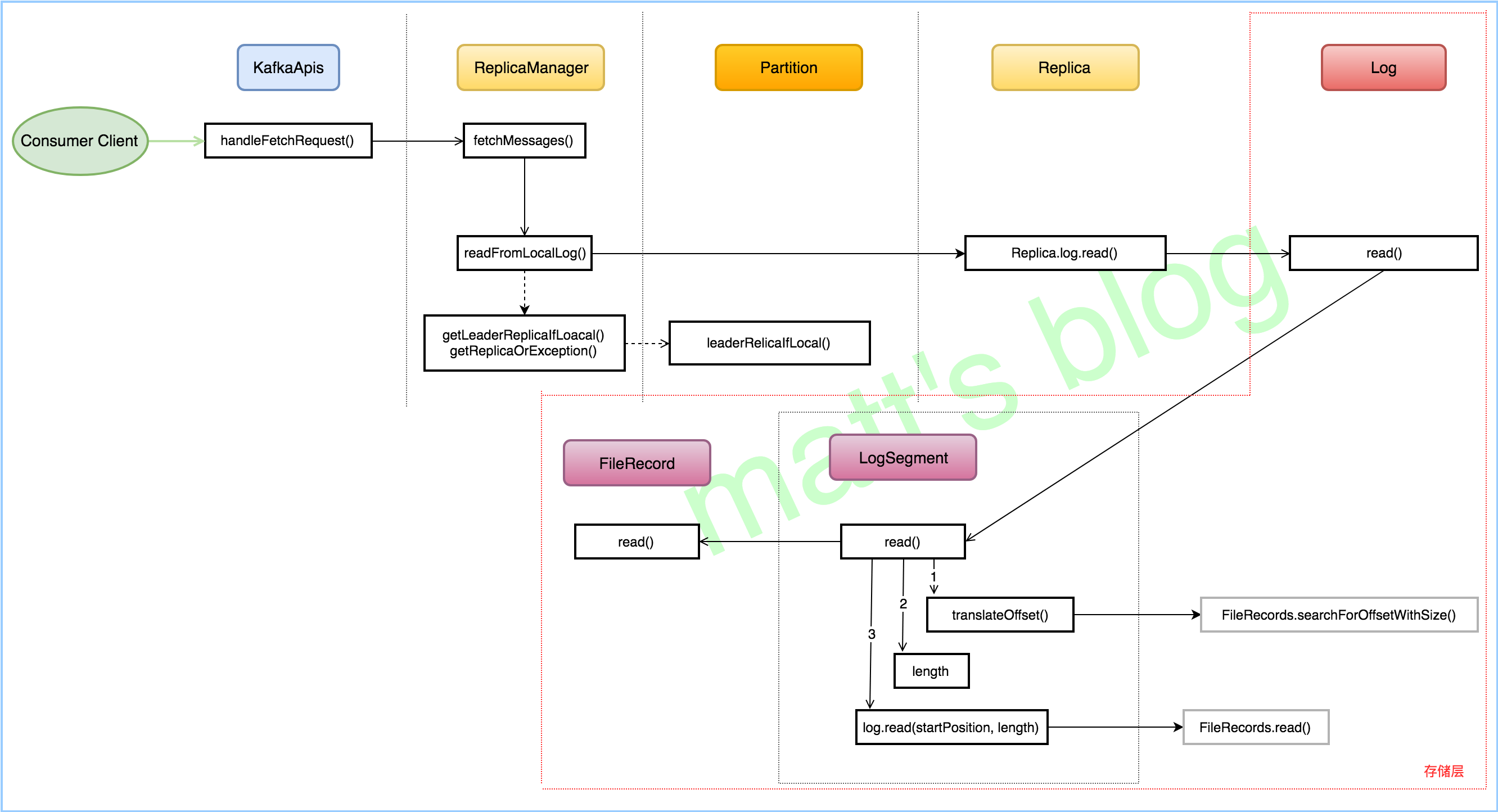
Fetch 请求处理的真正实现是在 replicaManager 的 fetchMessages() 方法中,在这里,可以看出,无论是 Fetch 请求还是 Produce 请求,都是通过副本管理器来实现的,副本管理器(ReplicaManager)管理的对象是分区实例(Partition),而每个分区都会与相应的副本实例对应(Replica),在这个节点上的副本又会与唯一的 Log 实例对应,正如流程图的上半部分一样,Server 就是通过这几部分抽象概念来管理真正存储层的内容。
ReplicaManager 如何处理 Fetch 请求
ReplicaManger 处理 Fetch 请求的入口在 fetchMessages() 方法。
fetchMessages()
整体来说,分为以下几步:
- readFromLocalLog():调用该方法,从本地日志拉取相应的数据;
- 判断 Fetch 请求来源,如果来自副本同步,那么更新该副本的 the end offset 记录,如果该副本不在 isr 中,并判断是否需要更新 isr;
- 返回结果,满足条件的话立马返回,否则的话,通过延迟操作,延迟返回结果。
readFromLocalLog()
处理过程:
- 先根据要拉取的 topic-partition 获取对应的 Partition 对象,根据 Partition 对象获取对应的 Replica 对象;
- 根据 Replica 对象找到对应的 Log 对象,然后调用其 read() 方法从指定的位置读取数据。
存储层对 Fetch 请求的处理
Log 对象
每个 Replica 会对应一个 log 对象,而每个 log 对象会管理相应的 LogSegment 实例。
read()
该方法会先查找对应的 Segment 对象(日志分段),然后循环直到读取到数据结束,如果当前的日志分段没有读取到相应的数据,那么会更新日志分段及对应的最大位置。
日志分段实际上是逻辑概念,它管理了物理概念的一个数据文件、一个时间索引文件和一个 offset 索引文件,读取日志分段时,会先读取 offset 索引文件再读取数据文件,具体步骤如下:
- 根据要读取的起始偏移量(startOffset)读取 offset 索引文件中对应的物理位置;
- 查找 offset 索引文件最后返回:起始偏移量对应的最近物理位置(startPosition);
- 根据 startPosition 直接定位到数据文件,然后读取数据文件内容;
- 最多能读到数据文件的结束位置(maxPosition)。
LogSegment
关乎 数据文件、offset 索引文件和时间索引文件真正的操作都是在 LogSegment 对象中的,日志读取也与这个方法息息相关。
read() in LogSegment
- 根据 startOffset 得到实际的物理位置(translateOffset());
- 计算要读取的实际物理长度;
- 根据实际起始物理位置和要读取实际物理长度读取数据文件。
translateOffset()
- 查找 offset 索引文件:调用 offset 索引文件的 lookup() 查找方法,获取离 startOffset 最接近的物理位置;
- 调用数据文件的 searchFor() 方法,从指定的物理位置开始读取每条数据,知道找到对应 offset 的物理位置。
offset索引文件
索引文件存储的是简单地索引数据,其格式为:「N,Position」。其中 N 表示索引文件里的第几条消息,而 Position 则表示该条消息在数据文件(Log File)中的物理偏移地址。
数据文件
数据文件就是所有消息的一个列表,而每条消息都有一个固定的格式。
如何读取消息
先在index文件中找到最接近offset的物理地址,这个过程可以用二分的方法查找,然后再根据物理地址从数据文件中读取消息。