1 | int *p[10] |
int *p[10]表示指针数组,强调数组概念,是一个数组变量,数组大小为10,数组内每个元素都是指向int类型的指针变量。
int (*p)[10]表示数组指针,强调是指针,只有一个变量,是指针类型,不过指向的是一个int类型的数组,这个数组大小是10。
int *p(int)是函数声明,函数名是p,参数是int类型的,返回值是int *类型的。
int (*p)(int)是函数指针,强调是指针,该指针指向的函数具有int类型参数,并且返回值是int类型的。
1 | int *p[10] |
int *p[10]表示指针数组,强调数组概念,是一个数组变量,数组大小为10,数组内每个元素都是指向int类型的指针变量。
int (*p)[10]表示数组指针,强调是指针,只有一个变量,是指针类型,不过指向的是一个int类型的数组,这个数组大小是10。
int *p(int)是函数声明,函数名是p,参数是int类型的,返回值是int *类型的。
int (*p)(int)是函数指针,强调是指针,该指针指向的函数具有int类型参数,并且返回值是int类型的。
报文上的区别
GET 和 POST 只是 HTTP 协议中两种请求方式,所以在传输上,没有区别,因为HTTP 协议是基于 TCP/IP 的应用层协议
报文格式上,不带参数时,最大区别仅仅是第一行方法名不同,一个是GET,一个是POST。
带参数时报文的区别呢?在约定中,GET方法的参数应该放在url中,POST方法参数应该放在body中。
举个例子,如果参数是 name=qiming.c, age=22。
GET 方法简约版报文可能是这样的:
GET /index.php?name=qiming.c&age=22 HTTP/1.1
Host: localhost
POST 方法简约版报文可能是这样的:
POST /index.php HTTP/1.1
Host: localhost
Content-Type: application/x-www-form-urlencoded name=qiming. c&age=22
传输数据的大小
在HTTP规范中,没有对URL的长度和传输的数据大小进行限制。但是在实际开发过程中,对于GET,特定的浏览器和服务器对URL的长度有限制。因此,在使用GET请求时,传输数据会受到URL长度的限制。
对于POST,由于不是URL传值,理论上是不会受限制的,但是实际上各个服务器会规定对POST提交数据大小进行限制,Apache、IIS都有各自的配置。
安全性
POST的安全性比GET的高。比如,在进行登录操作,通过GET请求,用户名和密码都会暴露再URL上,因为登录页面有可能被浏览器缓存以及其他人查看浏览器的历史记录的原因,此时的用户名和密码就很容易被他人拿到了。除此之外,GET请求提交的数据还可能会造成Cross-site request frogery攻击。
深入理解
GET和POST都是http请求方式,底层都是TCP/IP协议;通常GET 产生一个TCP数据包;POST产生两个TCP数据包(但firefox是发送一个数据包),
对于GET方式的请求,浏览器会把http header和data一并发送出去,服务器响应200(返回数据)表示成功;
而对于POST,浏览器先发送header,服务器响应100, 浏览器再继续发送data,服务器响应200 (返回数据)。
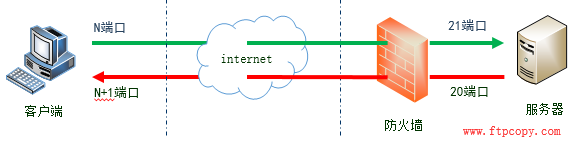
在主动模式下,客户端命令端口为N,数据端口为N+1,服务器端命令端口为21,数据端口为20。
第一步,客户端使用端口N连接FTP服务器的命令端口21,建立控制连接并告诉服务器我这边开启了数据端口N+1。
第二步,在控制连接建立成功后,服务器会使用数据端口20,主动连接客户端的N+1端口以建立数据连接。这就是FTP主动模式的连接过程。
我们可以看到,在这条红色的数据连接建立的过程中,服务器是主动的连接客户端的,所以称这种模式为主动模式。
主动模式的利弊
主动模式对FTP服务器的管理有利,因为FTP服务器只需要开启21端口的“准入”和20端口的“准出”即可。
但这种模式对客户端的管理不利,因为FTP服务器20端口连接客户端的数据端口时,有可能被客户端的防火墙拦截掉。
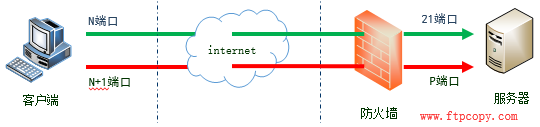
在被动模式下,客户端命令端口为N,数据端口为N+1,服务器端命令端口为21,数据端口为P。
第一步,客户端的命令端口N主动连接服务器命令端口21,并发送PASV命令,告诉服务器用“被动模式”,控制连接建立成功后,服务器开启一个数据端口P,通过PORT命令将P端口告诉客户端。
第二步,客户端的数据端口N+1去连接服务器的数据端口P,建立数据连接。
我们可以看到,在这条红色的数据连接建立的过程中,服务器是被动的等待客户端来连接的,所以称这种模式为被动模式。
被动模式利弊
被动模式对FTP客户端的管理有利,因为客户端的命令端口和数据端口都是“准出”,windows防火墙对于“准出”一般是不拦截的,所以客户端不需要任何多余的配置就可以连接FTP服务器了。
但对服务器端的管理不利。因为客户端数据端口连到FTP服务器的数据端口P时,很有可能被服务器端的防火墙阻塞掉。
http状态码的由三位数字和原因短语组成,数字的第一位数字表示响应的类别,后面两位无类别。
| 状态码 | 原因 |
|---|---|
| 1XX | 临时状态码,表示正在处理请求 |
| 2XX | 请求处理成功 |
| 3XX | 重定向,表示要完成请求需要进一步操作 |
| 4XX | 请求错误,错误的原因在客户端,比如请求的参数错误或者url过长等 |
| 5XX | 服务器错误,比如服务不可用或者服务器内部出错 |
已通过
自我介绍
问项目
问基础知识
虚拟内存是什么有什么用?(因为我在项目提到了内存缺页算法LRU)
函数调用是怎么实现的?(因为我项目有编译器,就回答了一下栈结构,函数参数返回值压栈弹栈之类的,细节忘了)
堆、栈、寄存器哪些是线程独有的,哪些事线程共享的?(不会,想了一会儿回答寄存器肯定是独有的因为涉及到CPU环境切换,堆栈不确定,又想了一下回答了堆栈也是独有的,他说好的没关系,应该是答错了。。)
两个线程都执行a++100次,a的结果是多少?(犹豫了半天还是说了200,感觉不能这么简单吧)
答案应该是2~200(https://blog.csdn.net/speargod/article/details/96651069)
tcp四次挥手为什么比三次握手多一次?(服务器要把没传完的数据传完才能再发起FIN请求)
网络拥塞、拥塞控制、流量控制相关知识。
打开一个网页的过程?(主要回答了域名解析的过程)
https和http的区别?(加了个SSL实现加密传输)
SSL是怎么实现加密传输的?(大概说了一下,先用非对称加密交换通信秘钥,然后用通信秘钥进行对称加密通信)
http的错误码?(不怎么了解,看我皱了下眉头就说没关系不问了)
数据库里的事务是什么?
用户输入密码怎么保证安全?(没搞懂他想问的是什么。。)
讨论:用户在PC登陆微信时,可以用手机扫码登陆,这是怎么实现的,想聊什么聊什么。
算法题
大鱼吃小鱼问题
一个数字序列,每个元素都代表一条鱼,正数表示鱼向右游,负数表示向左游,数字的绝对值代表鱼的体积,如果两条鱼相撞则大鱼会吃掉小鱼,如果相撞的两条鱼大小相等则都会死亡。鱼游的速度都相同,问最后剩下哪些鱼?
写了个n^2的暴力算法,应该还可以优化。。最后简单说了一下优化的思路,细节没想清楚也不确定对不对,面试官就说差不多了,没有让继续写下去。
优化思路:
开一个数组记录鱼的存活状态,初始值是全true。
从左往右遍历的时候记录一个值表示往右游的鱼的最大值,遇到一个往右游的就更新一下最大值,遇到一个往左游的就比较大小。
如果往左游的小那就被吃掉,反之认为左边所有往右游的鱼都会被这条往左游的鱼吃掉(因为最大的都比它小),则将最大值置为0继续往右遍历,一直遍历到结尾。
然后从右往左反方向遍历一遍,做同样的操作。
面试官是真的好,很和善,会引导你回答问题。
堆、栈、寄存器哪些是线程独有的,哪些事线程共享的?
堆:是大家共有的空间,分全局堆和局部堆。全局堆就是所有没有分配的空间,局部堆就是用户分配的空间。堆在操作系统对进程初始化的时候分配,运行过程中也可以向系统要额外的堆,但是记得用完了要还给操作系统,要不然就是内存泄漏。
栈:是个线程独有的,保存其运行状态和局部自动变量的。栈在线程开始的时候初始化,每个线程的栈互相独立,因此,栈是 thread safe的。操作系统在切换线程的时候会自动的切换栈,就是切换 SS/ESP寄存器。栈空间不需要在高级语言里面显式的分配和释放。
寄存器这里不太确定,因为寄存器数量是有限的,所以每个线程在执行时应该用的都是这些寄存器,所以从这个角度来说好像是共享的。但是每个线程执行时寄存器的内容是不能被别的线程访问的,所以应该又是独有的。。。总的来说寄存器应该是独有的吧。。。
函数调用是怎么实现的?
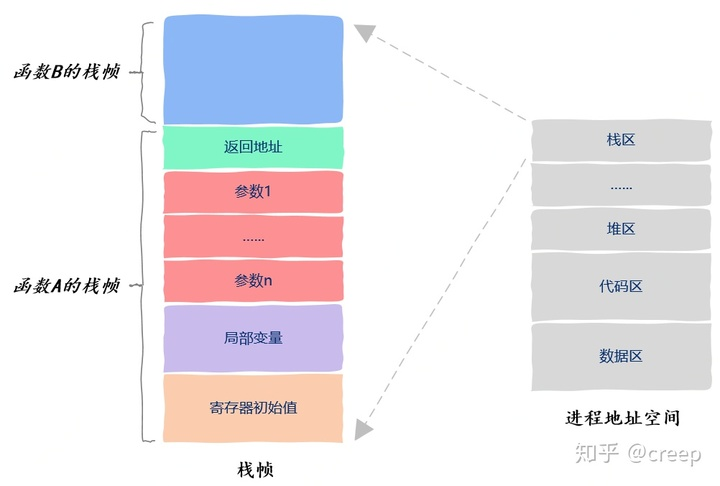
栈帧,也就是stack frame,其本质就是一种栈,只是这种栈专门用于保存函数调用过程中的各种信息(参数,返回地址,本地变量等)。栈帧有栈顶和栈底之分,其中栈顶的地址最低,栈底的地址最高,SP(栈指针)就是一直指向栈顶的。在x86-32bit中,我们用 %ebp 指向栈底,也就是基址指针;用 %esp 指向栈顶,也就是栈指针。下面是一个栈帧的示意图:
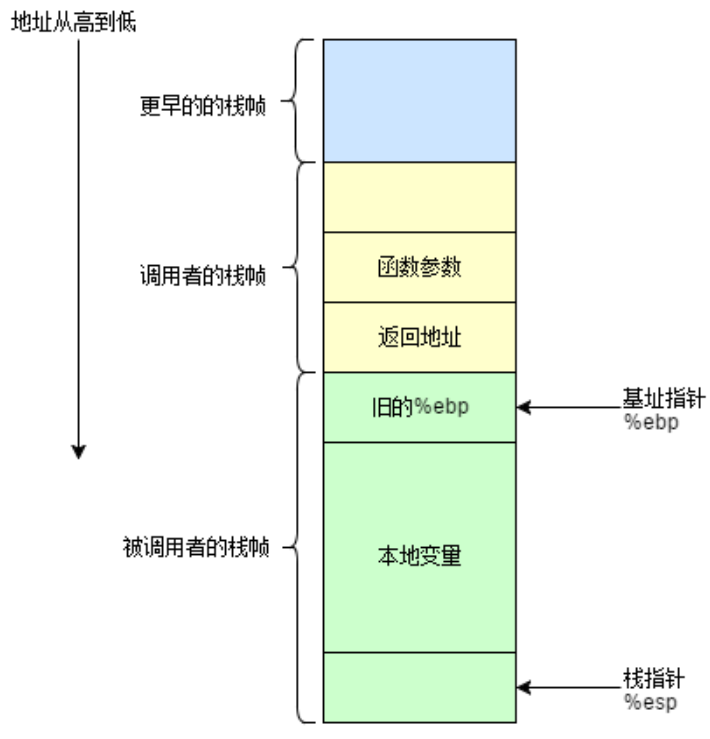
一般来说,我们将 %ebp 到 %esp 之间区域当做栈帧(也有人认为该从函数参数开始,不过这不影响分析)。并不是整个栈空间只有一个栈帧,每调用一个函数,就会生成一个新的栈帧。在函数调用过程中,我们将调用函数的函数称为“调用者(caller)”,将被调用的函数称为“被调用者(callee)”。在这个过程中,1)“调用者”需要知道在哪里获取“被调用者”返回的值;2)“被调用者”需要知道传入的参数在哪里,3)返回的地址在哪里。同时,我们需要保证在“被调用者”返回后,%ebp, %esp 等寄存器的值应该和调用前一致。因此,我们需要使用栈来保存这些数据。