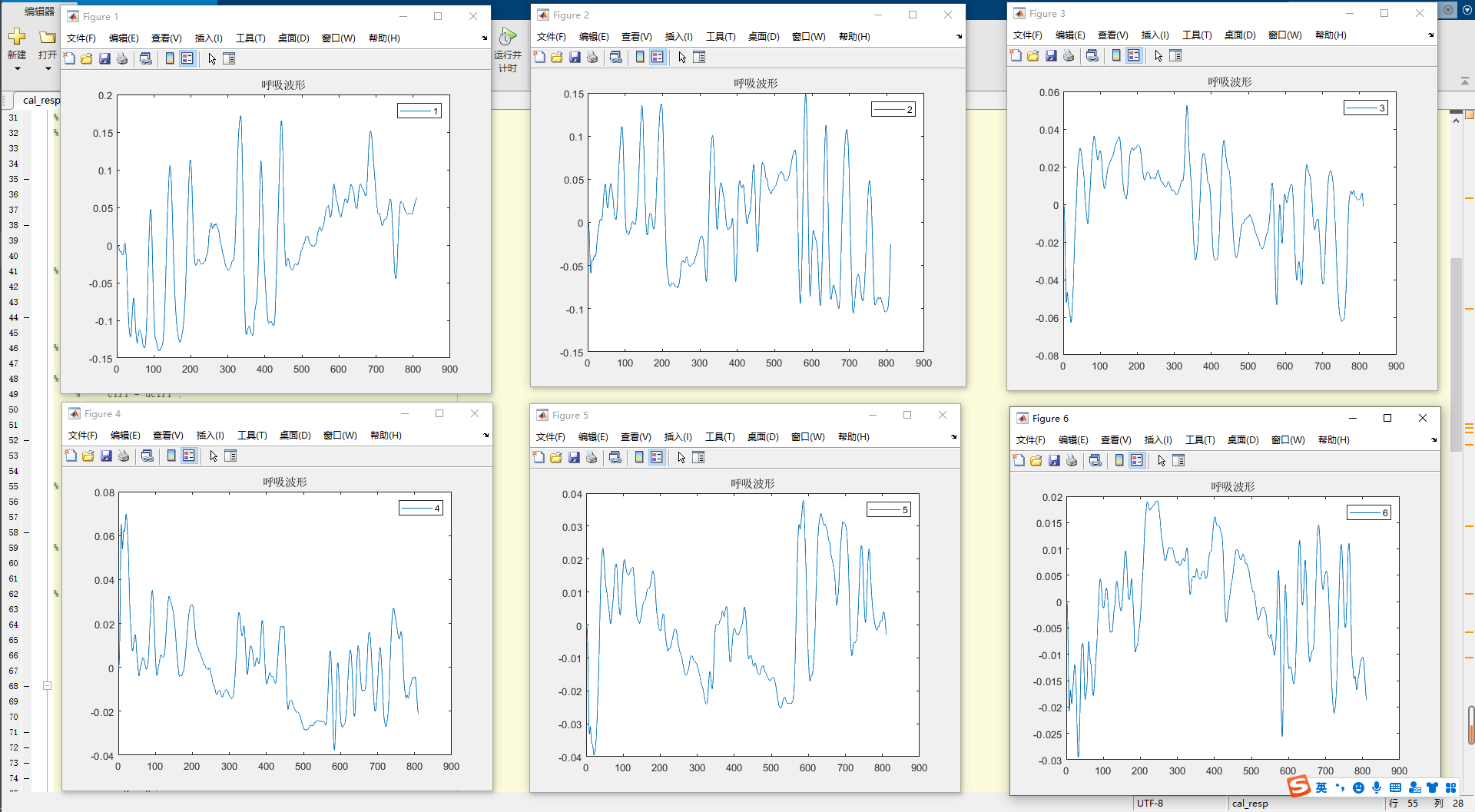
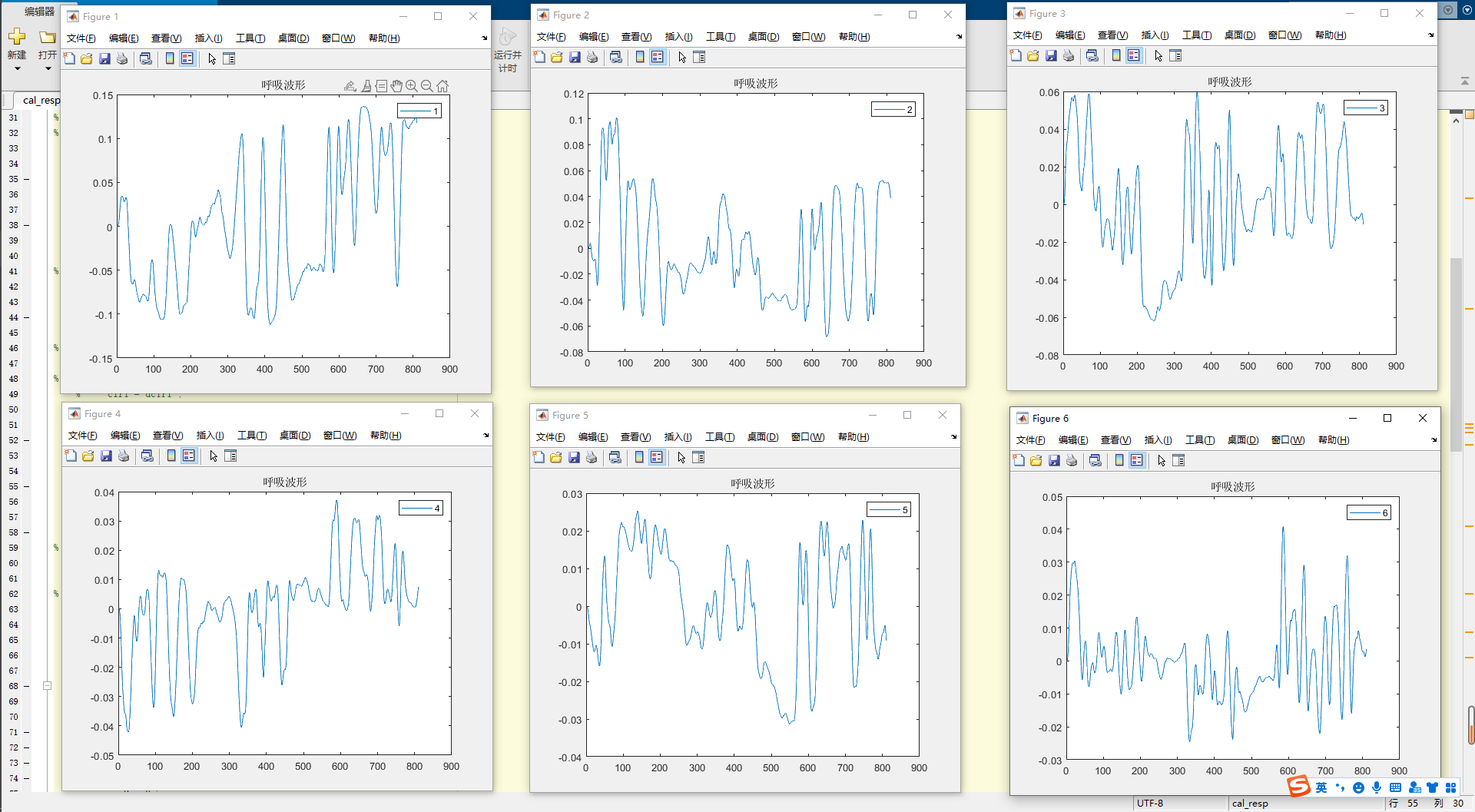
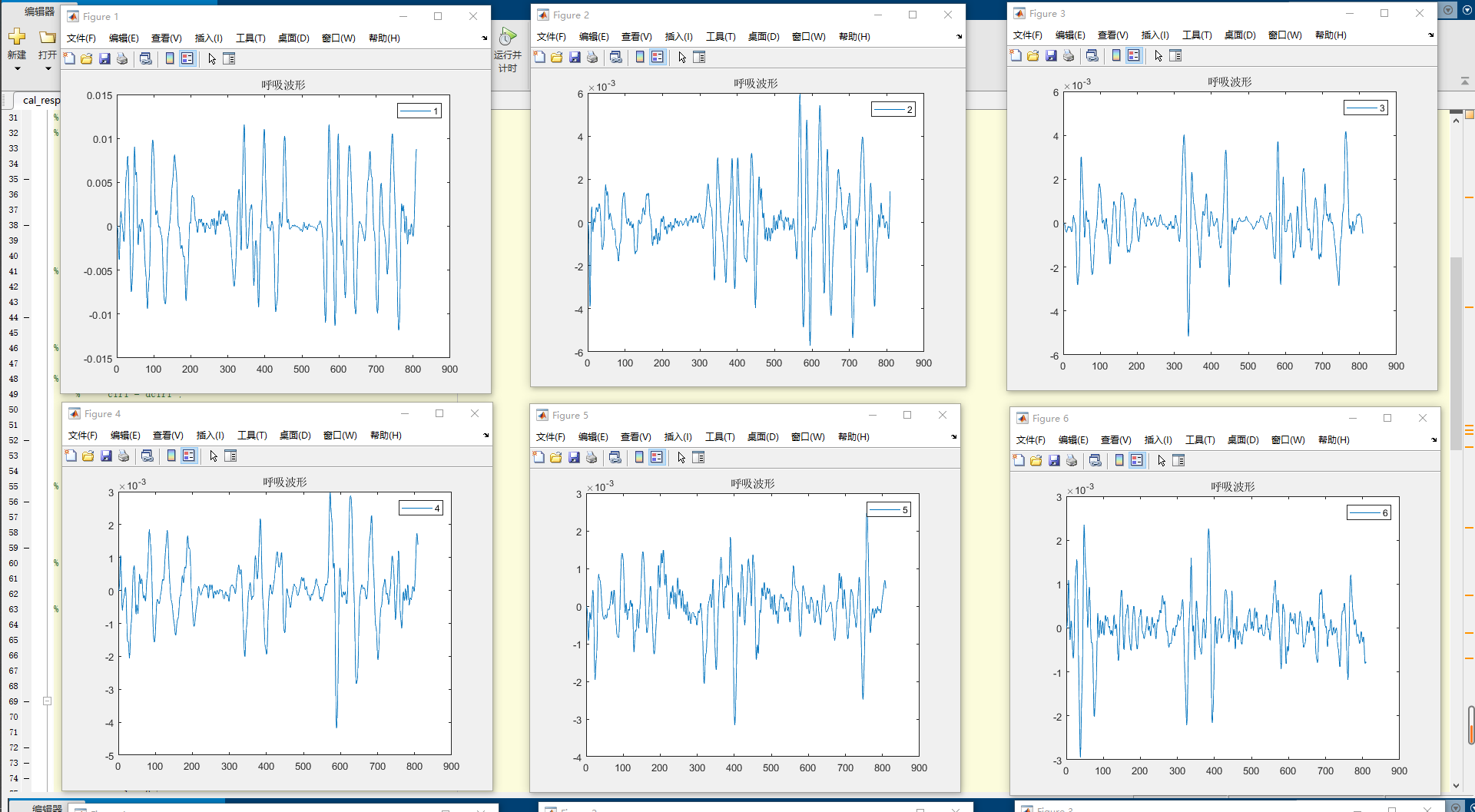
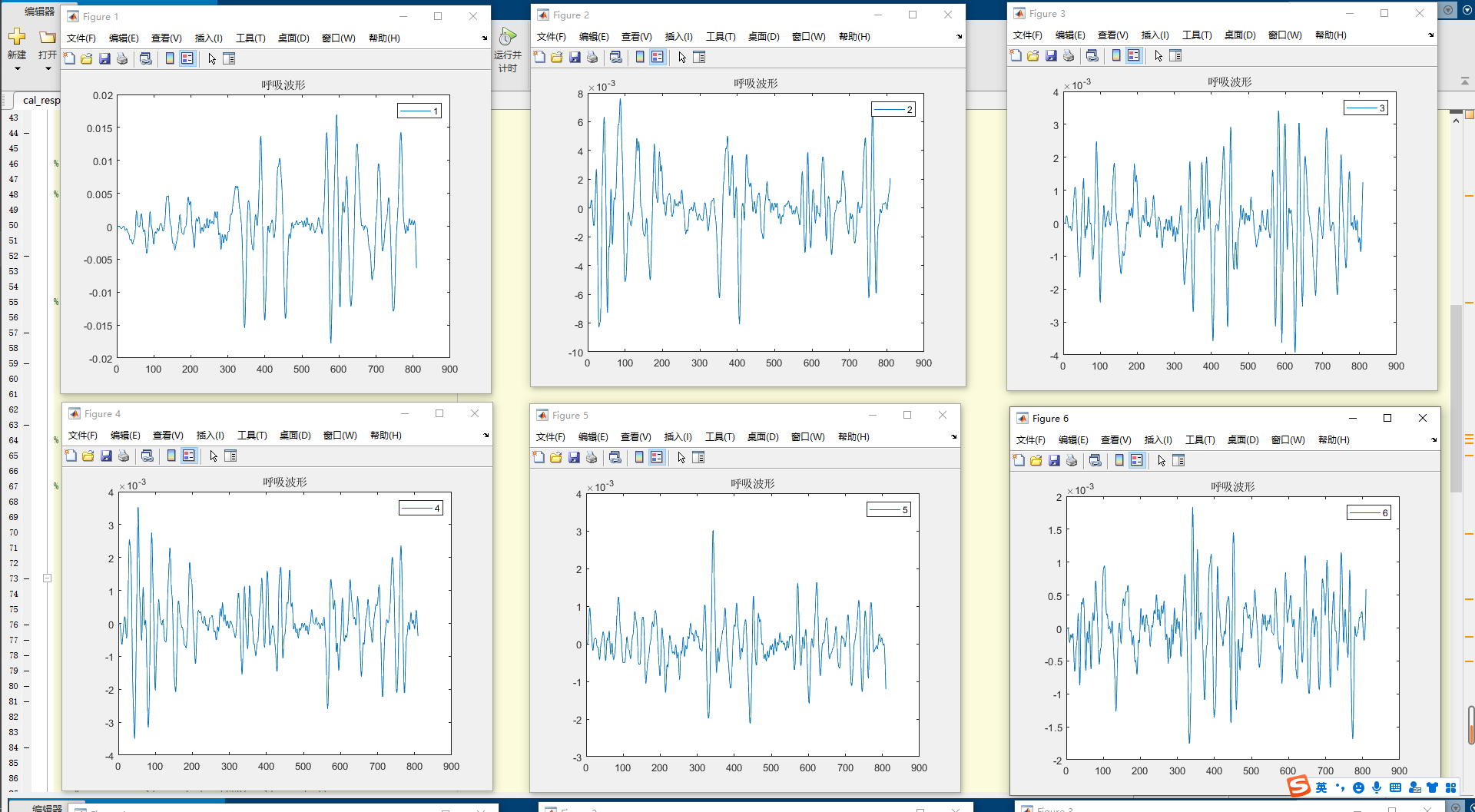
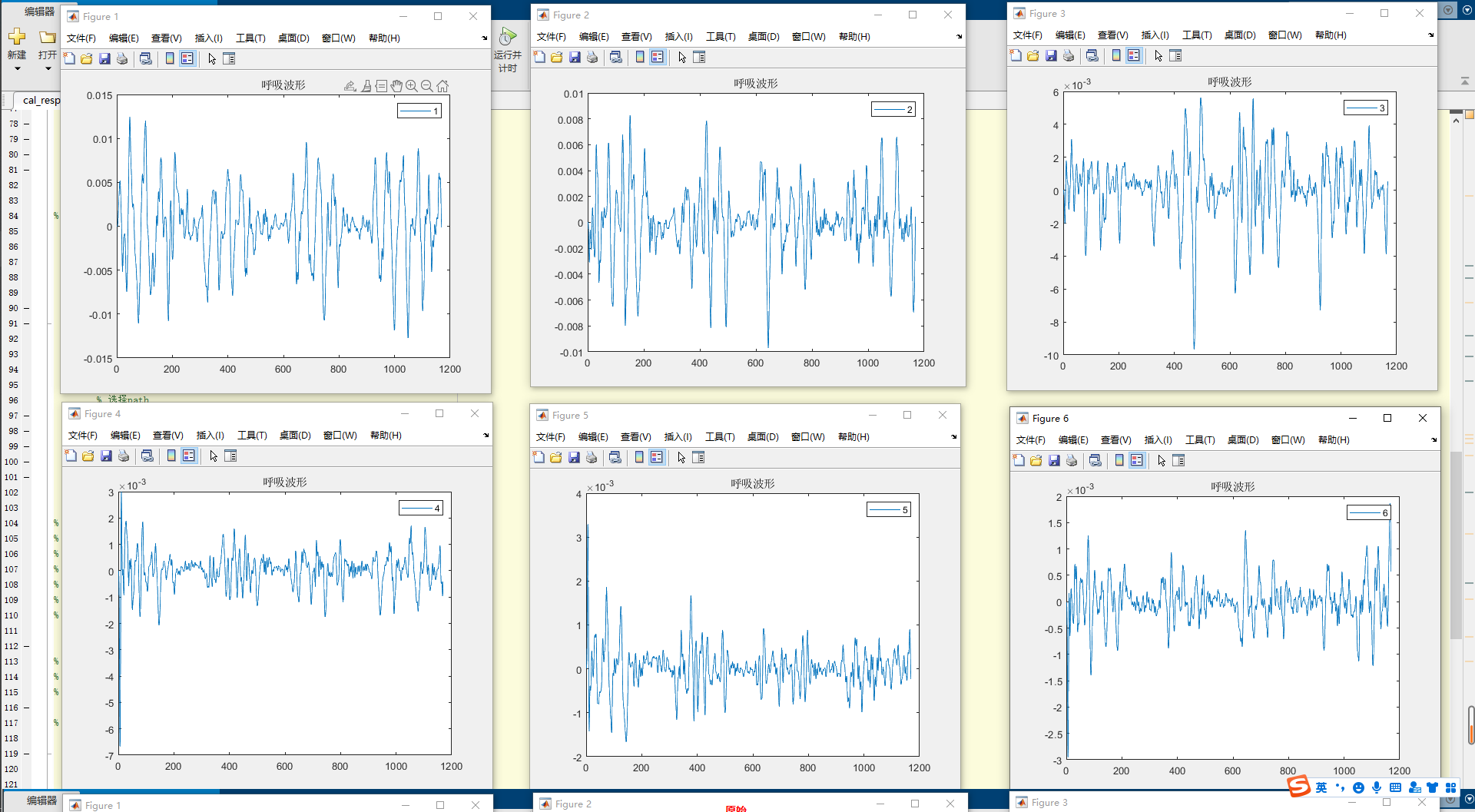
不同的继承方式会影响基类成员在派生类中的访问权限。
- public继承方式
- 基类中所有 public 成员在派生类中为 public 属性;
- 基类中所有 protected 成员在派生类中为 protected 属性;
- 基类中所有 private 成员在派生类中不能使用。
- protected继承方式
- 基类中的所有 public 成员在派生类中为 protected 属性;
- 基类中的所有 protected 成员在派生类中为 protected 属性;
- 基类中的所有 private 成员在派生类中不能使用。
- private继承方式
- 基类中的所有 public 成员在派生类中均为 private 属性;
- 基类中的所有 protected 成员在派生类中均为 private 属性;
- 基类中的所有 private 成员在派生类中不能使用。
默认是私有继承