RecordAccumulator
- 每个 topic-partition 都有一个对应的 deque,deque 中存储的是 RecordBatch,它是发送的基本单位,只有这个 topic-partition 的 RecordBatch 达到大小或时间要求才会触发发送操作(但并不是只有达到这两个条件之一才会被发送,这点要理解清楚)。
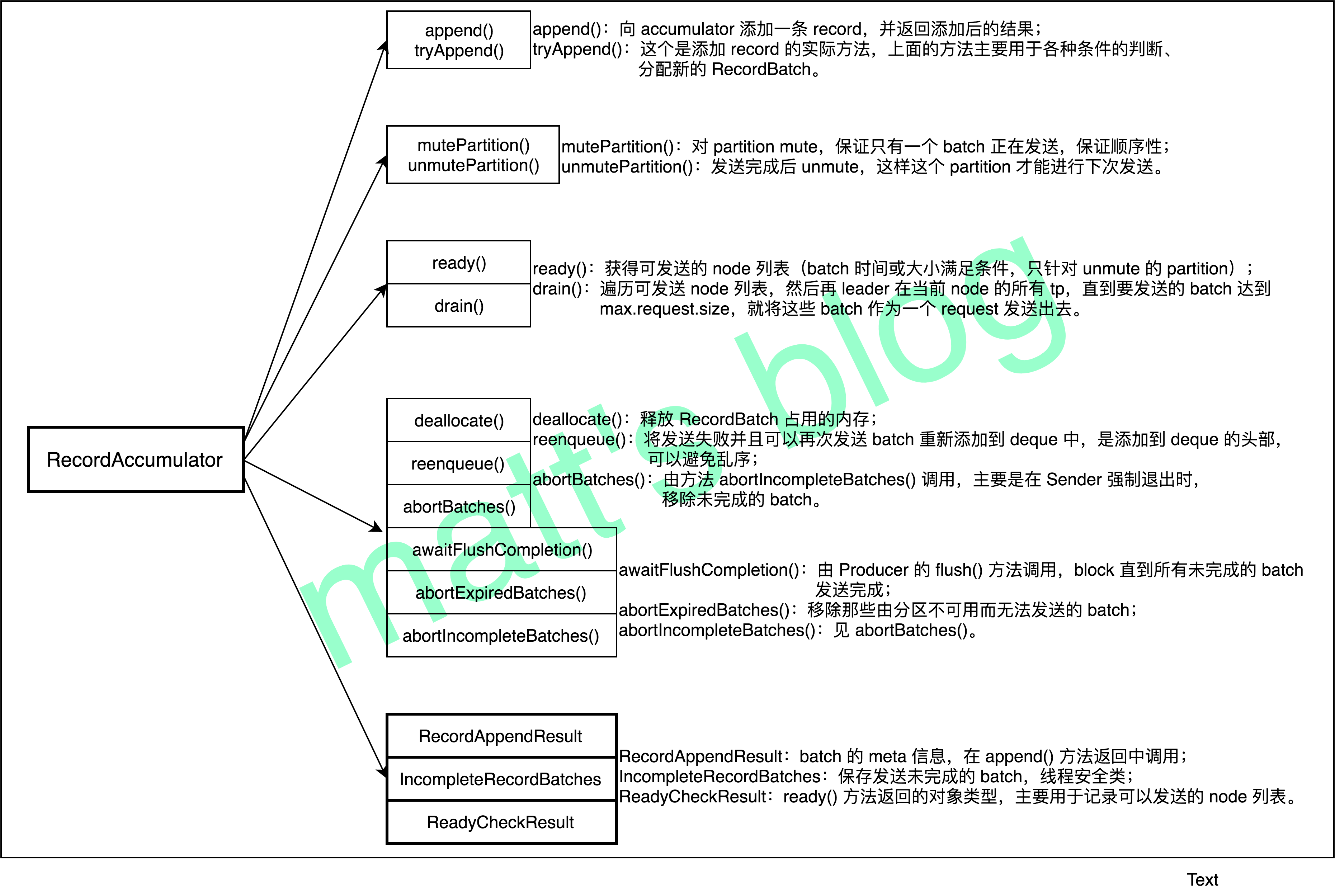
- 每个 topic-partition 都有一个对应的 deque,deque 中存储的是 RecordBatch,它是发送的基本单位,只有这个 topic-partition 的 RecordBatch 达到大小或时间要求才会触发发送操作(但并不是只有达到这两个条件之一才会被发送,这点要理解清楚)。
mutePartition() 与 unmutePartition()
- 这两个方法是保证有序性关键之一,其主要做用就是将指定的 topic-partition 从 muted 集合中加入或删除。
- mutePartition():如果要求保证顺序性,那么这个 tp 对应的 RecordBatch 如果要开始发送,就将这个 tp 加入到 muted 集合中;
- unmutePartition():如果 tp 对应的 RecordBatch 发送完成,tp 将会从 muted 集合中移除。
ready()
- ready() 是在 Sender 线程中调用的,其作用选择那些可以发送的 node,也就是说,如果这个 tp 对应的 batch 可以发送(达到时间或大小要求),就把 tp 对应的 leader 选出来。
drain()
- 是用来遍历可发送请求的 node,然后再遍历在这个 node 上所有 tp,如果 tp 对应的 deque 有数据,将会被选择出来直到超过一个请求的最大长度(max.request.size)为止,也就说说即使 RecordBatch 没有达到条件,但为了保证每个 request 尽快多地发送数据提高发送效率,这个 RecordBatch 依然会被提前选出来并进行发送。
顺序性如何保证?
- 如果 KafkaProducer 的 max.in.flight.requests.per.connection 设置为1,那么就可以保证其顺序性,否则的话,就不保证顺序性
- 而其实现机制则是在 RecordAccumulator 中的 mutePartition() 与 unmutePartition()
kafka中的Topic
topic的创建
- 通过 kafka-topics.sh 创建一个 topic,可以设置相应的副本数让 Server 端自动进行 replica 分配,也可以直接指定手动 replica 的分配;
- Server 端如果 auto.create.topics.enable 设置为 true 时,那么当 Producer 向一个不存在的 topic 发送数据时,该 topic 同样会被创建出来,此时,副本数默认是1。
- 无论使用哪种方式,最后都是通过 AdminUtils.createOrUpdateTopicPartitionAssignmentPathInZK() 将 topic 的 Partition replicas 的更新到 zk 上,这中间关键的一点在于:Partition 的 replicas 是如何分配的。在创建时,我们既可以指定相应 replicas 分配,也可以使用默认的算法自动分配。
replica的分配
- 创建时指定 replicas 分配
- replicas 自动分配算法
- 在创建 topic 时,Server 通过 AdminUtils.assignReplicasToBrokers() 方法来获取该 topic partition 的 replicas 分配。
- 从 broker.list 随机选择一个 Broker,使用 round-robin 算法分配每个 partition 的第一个副本;
- 对于这个 partition 的其他副本,逐渐增加 Broker.id 来选择 replica 的分配。
partition的状态
- NonExistentPartition:这个 partition 不存在;
- NewPartition:这个 partition 刚创建,有对应的 replicas,但还没有 leader 和 isr;
- OnlinePartition:这个 partition 的 leader 已经选举出来了,处理正常的工作状态;
- OfflinePartition:partition 的 leader 挂了。
- partition 只有在 OnlinePartition 这个状态时,才是可用状态。
kafka中的Metadata
Metadata的内容
- Metadata元数据主要包含了broker、topic和partition的信息,比如broker的id、topic的partition数、partition的leader和副本等
- 集群中有哪些节点;
- 集群中有哪些 topic,这些 topic 有哪些 partition;
- 每个 partition 的 leader 副本分配在哪个节点上,follower 副本分配在哪些节点上;
- 每个 partition 的 AR 有哪些副本,ISR 有哪些副本
Metadata的应用场景
- KafkaProducer 发送一条消息到指定的 topic 中,需要知道分区的数量,要发送的目标分区,目标分区的 leader,leader 所在的节点地址等,这些信息都要从 Metadata 中获取。
- 当 Kafka 集群中发生了 leader 选举,节点中 partition 或副本发生了变化等,这些场景都需要更新Metadata 中的数据
Metadata的更新
- Producer 在调用 dosend() 方法时,第一步就是通过 waitOnMetadata 方法获取该 topic 的 metadata 信息。如果metadata读不到,会一直阻塞在那,直到超时,抛出TimeoutException。
- Sender poll()更新Metadata
- 周期性的更新: 每隔一段时间更新一次,这个通过 Metadata的lastRefreshMs, lastSuccessfulRefreshMs 这2个字段来实现
- 失效检测,强制更新:检查到metadata失效以后,调用metadata.requestUpdate()强制更新。 requestUpdate()函数里面其实什么都没做,就是把needUpdate置成了false
Metadata失效检测
- initConnect的时候
- poll里面IO的时候,连接断掉了
- 有请求超时
- 发消息的时候,有partition的leader没找到
- 返回的response和请求对不上的时候
- 总之一句话:发生各式各样的异常,数据不同步,都认为metadata可能出问题了,要求更新。
kafka中的Producer
- 发送数据
- Producer通过producer.send()函数发送数据
- send发送的是record,record包含了message的topic和value,可选的还有key和partition等
- 发送之前需要先把key和value序列化,序列化就是将其变成字节流,对于一般类型kafka已经内置了序列化和反序列化函数,复杂类型的可能需要自己实现
- 获取partition的值,producer发送消息的时候需要确定发送到哪个topic的哪个partition
- 指明partition的情况下,直接发送到指明的partition
- 没指明partition的情况下,将key的hash值与partition个数取余作为partition值
- 如果连key都没有的话,则随机一个整数对partition个数取余作为partition值,之后每次都自增,即round-robin算法
- 向accumulator写数据
- 每个topic-partition都会有一个队列,队列的单元是recordbatch
- producer要发送的record先追加到recordbatch中,如果不存在或者空间不足则新建一个recordbatch
- 写入成功后,如果发现有recordbatch满足发送条件,就会唤醒sender线程发送recordbatch
- 将broker相同的recordbatch放在一起发送
kafka中的HW
isr列表:inSyncReplicas,分区中与leader副本保持一定程度同步的副本成为isr,这个是与副本同步有关的,就是说,如果你partition的follower副本会去leader副本上拉取数据同步到follower副本中,这个时候follower副本的leo也是会增加的,每拉过来一条数据follower副本的leo就会+1,然后如果你这个follower 副本的leo追上了leader的hw,就会将这个follower副本添加到isr列表中,如果过段时间发现这个follower 好长时间没有拉取数据了,就会将它从isr列表中剔除。
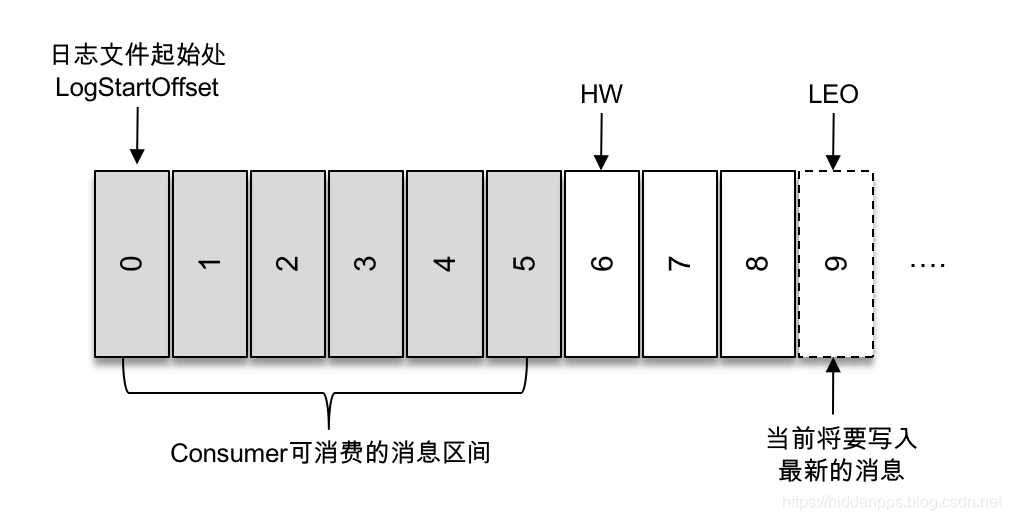
logStartOffset,日志中第一条消息的offset,副本的拉取请求(FetchRequest)和删除请求(DeleteRecordRequest)有可能触发新建日志分段而旧的的被清理,进而导致logStartoffset的增加。
LW(Low Watermark),俗称“低水位”,代表AR集合中最小的logStartOffset值。
logEndOffset,日志中将要写入的新消息的offset,最后一条消息的offset+1。
HW(High Watermak),俗称“高水位”,代表ISR中最小的logEndOffset,它表示了一个特定消息的偏移量(offset),消费之只能拉取到这个offset之前的消息。